There are a few specific situations where the database project cannot be realistically deployed using release automation. Here are two scenarios that generally force us to manually deploy changes:
- A new non-nullable column needs to be added to an existing table with a default constraint
- An index needs to be changed
Typically, these situations arise when the table is very large and/or the deployment requires multiple schema changes that have to be deployed in a sequential order. In any of these cases we simply execute the changes manually on the database using a script then commit the changes to source control so the project reflects what the new database schema looks like. When the automated deployment executes it doesn't actually make any changes because they're already in place.
All-in-all, I'm very happy with the database projects and I would recommend using them.
The Publish Profile
When the database schema is published to the database server, it is recommended to use a publish profile. A publish profile defines all of the rules that control the behavior of the publish. In our case, one of the rules we enforce is keyword case sensitivity. We enable this rule in both the project and in the publish profile. Some would argue that if you're using a case insensitive collation such as SQL_Latin1_General_CP1_CI_AS then you don't need to enforce keyword case sensitivity in the database project. Aside from code aesthetics, there are some very specific performance reasons for having consistently written T-SQL statements.
According to Microsoft KB Article 263889 having inconsistent stored procedure casing could cause cache misses
"the request for a COMPILE lock can cause a "blocking chain" situation if there are many SPIDs trying to execute the same procedure with a different case ... the algorithm that is being used to find the procedure in cache is based on hash values (for performance reasons), which can change if the case is different"
This kind of behavior also applies to ad-hoc statements being executed. In general, enforcing case sensitivity in your database code is a good thing.
I Am Seeing Objects Being Dropped and Recreated
I've recently noticed in our deployment logs that many constraints and even some indexes were being consistently dropped and recreated. During some of the database publish tasks the log showed over 100 objects being dropped and recreated.
I even found a Microsoft Connect issue opened for this problem that remains unresolved since 2013: https://connect.microsoft.com/VisualStudio/feedback/details/793433/ssdt-generated-script-drops-and-re-adds-default-and-check-constraints-every-time
This problem was baffling me. I even have several database schema compare projects (.scmp) configured and saved in each solution (to create one, right-click the database project and select Compare Schema to generate a corresponding .scmp file). I use these compare profiles to verify what will change when my database project gets published. It's handy and I recommend doing the same and using it prior to checking in your code.
I See No Differences In The Compare Project, So What's the Problem?
I use the same options in the schema compare project that I use in the publish profile... or so I thought. Configuring the schema compare project is a bit tricky because the options to configure the compare project aren't represented the same way that the options to configure the publish profile are. I finally discovered, thanks to this helpful Stack post, that my compare profile was missing a setting! There is an option called ignore keyword casing that the publish profile had unchecked (because we want a case-sensitive comparison) but the schema compare project had checked.
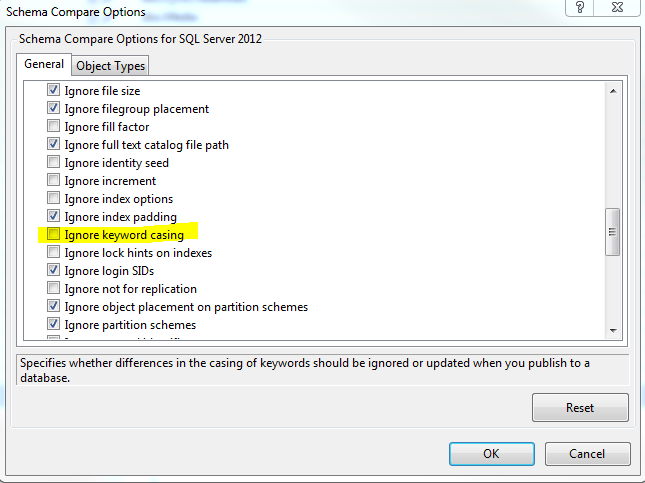
With the option unchecked I am now able to see the issue.
So What Was the Issue?
The root cause of the issue is that when the compiled project file (or .dacpac file) is being compared with the actual SQL Server database, the way that the schema is represented on the SQL Server side may be slightly syntactically different than the way the script is defined in the project. This is detected as a difference so SSDT tries to drop and recreate the object to make them consistent.
Here are some examples that I found repeated throughout the database projects that I work with:
How do I fix it?
The only way to fix this issue is to review the differences with the schema compare project and edit the code in the project so it is in the same format that SSDT is detecting it in SQL Server.Here are some examples that I found repeated throughout the database projects that I work with:
- Some system functions are represented as lowercase in SQL Server like sysutcdatetime(), getutcdate(), and newid()
- Scalar numerical values in default constraints need to be enclosed in double parenthesis ((0)), but I noticed that string values do not
- Filtered index and check constraint conditions must be enclosed in parenthesis (), the column names must be in square brackets, and the comparison operator must not have spaces between the left and right side (e.g. WHERE ([myCol]=(1)) )
- Some columns must be enclosed in square brackets []
Conclusion
It was a bit of a headache for a few days until I figured out the problem. With the comparison project options set correctly I was eventually able to review all of the projects and fix these issues which reduced the overall publish duration significantly in a few cases. It would be best if Microsoft addressed the Connect issue, but this is one issue that can be reasonably managed fairly easily once you know what to look for, it just takes some due diligence.
Thanks for reading, I hope this helped a few of you out there!


